Skip to contentMy Articles
2025
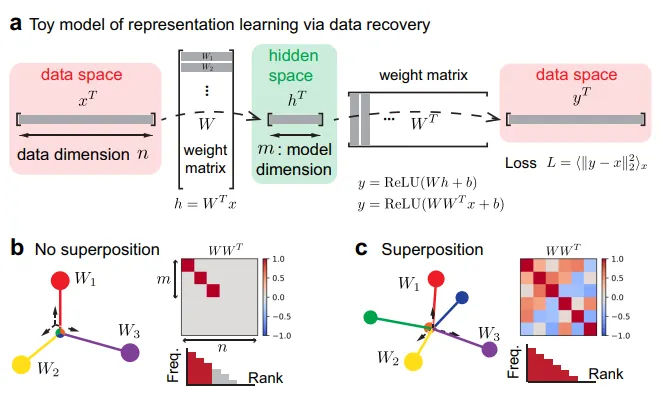
Why Do LLMs Get Smarter as They Get Bigger? The Hidden Geometry of “Superposition”
2025
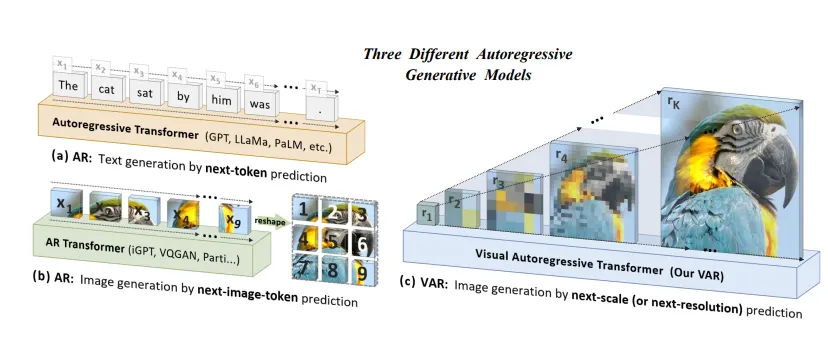
Beyond Diffusion: How Visual Autoregressive Modeling (VAR) Rewrites the Rules of Image Generation
2025
Breaking the Transformer Bottleneck: Gating for Scaled Non-Linearity and “Attention-Sink-Free” LLMs
2025
Beyond RAG: Why CLaRa’s “Latent Reasoning” Changes the Game for Retrieval-Augmented Generation
2025
KAN: The Shift from Fixed Nodes to Learnable Edges
2025
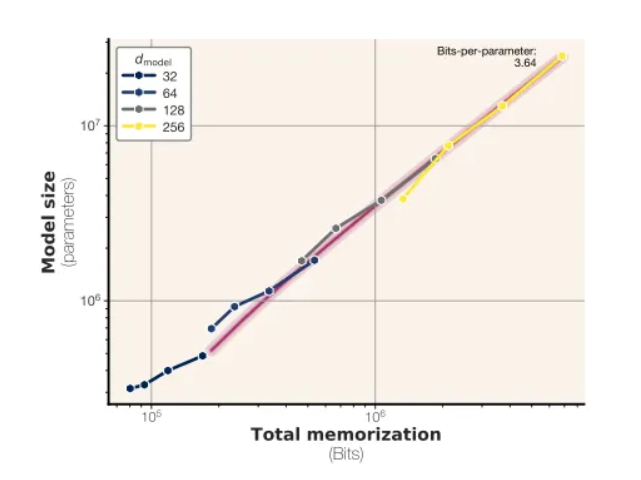
The Magic Number is 3.6: Measuring the True Capacity of Large Language Models
2025
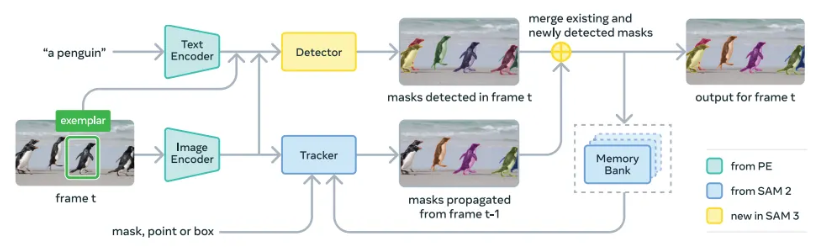
Beyond the Click: Inside the Architecture of SAM 3 and Promptable Concept Segmentation
2025
We’ve Been Overcomplicating Diffusion: Why “Just Image Transformers” Are All You Need
2025
Nested Learning: A Technical Reflection on a New Way to Think About Deep Learning
2025
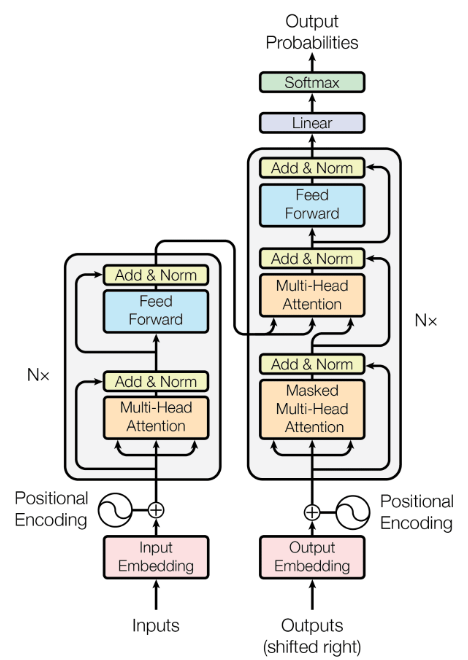
The Transformer Paradigm: Rethinking Sequence Modeling Through Attention
2025
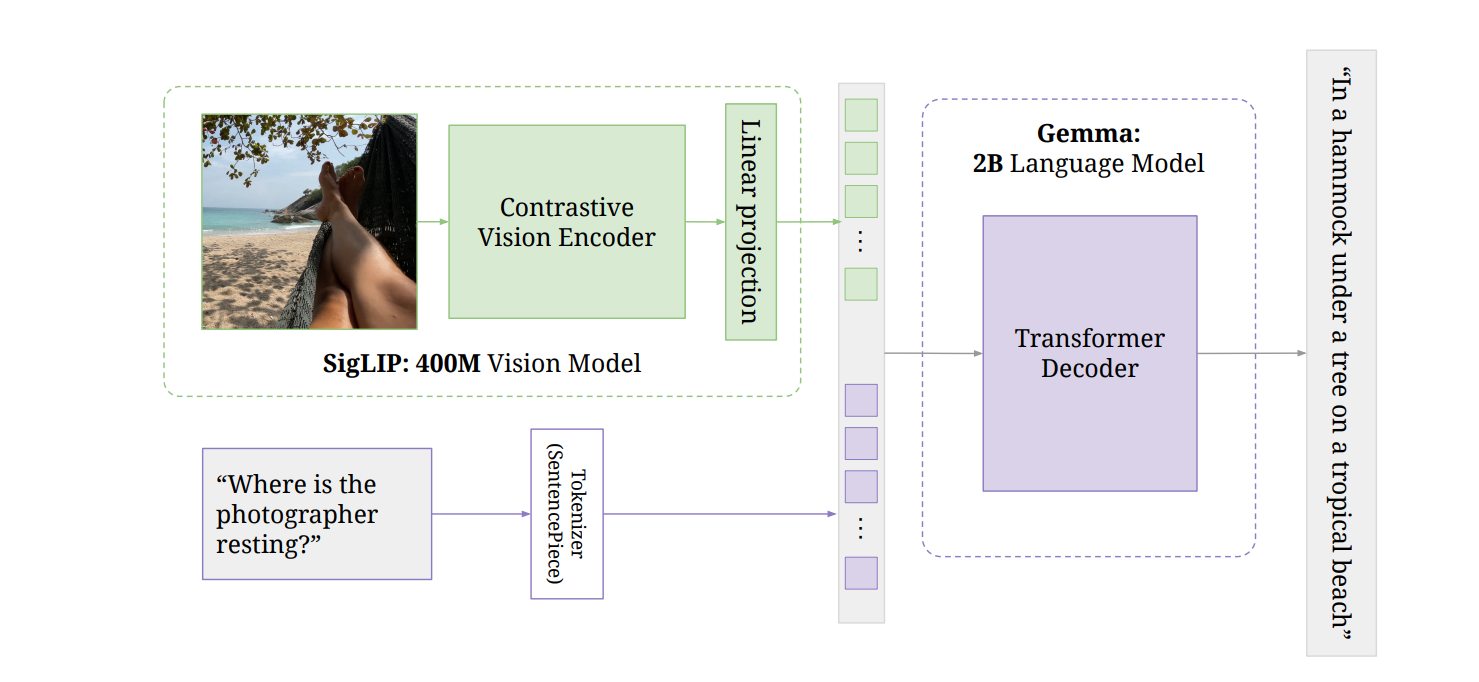
Inside PaliGemma: Building an Open, Transferable 3B Vision-Language Model
2025
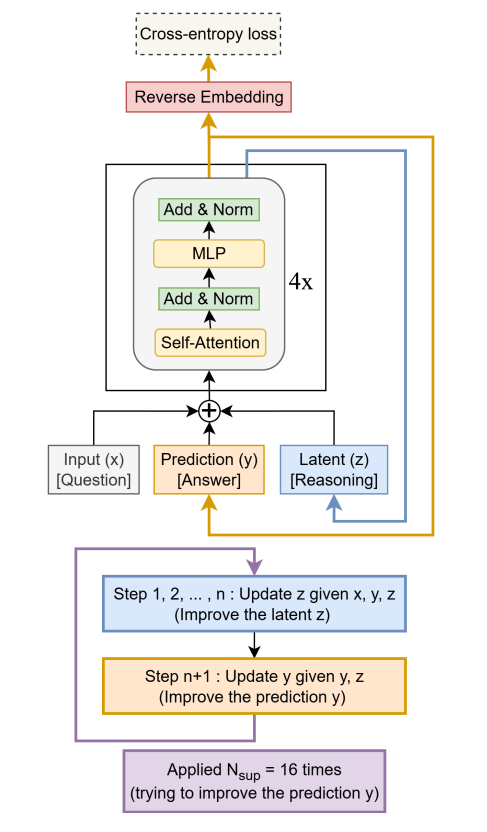
Less Is More: My Deep Dive into Recursive Reasoning with Tiny Networks
 2025
2025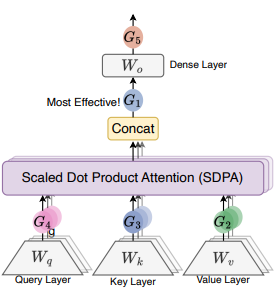 2025
2025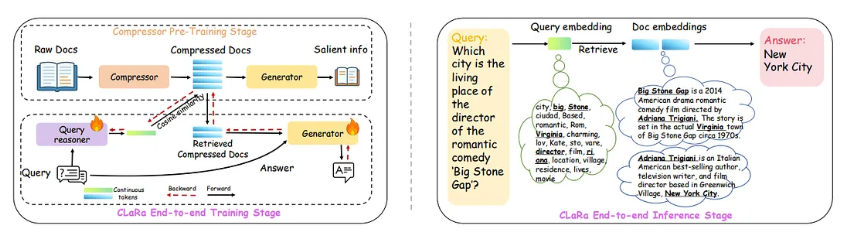 2025
2025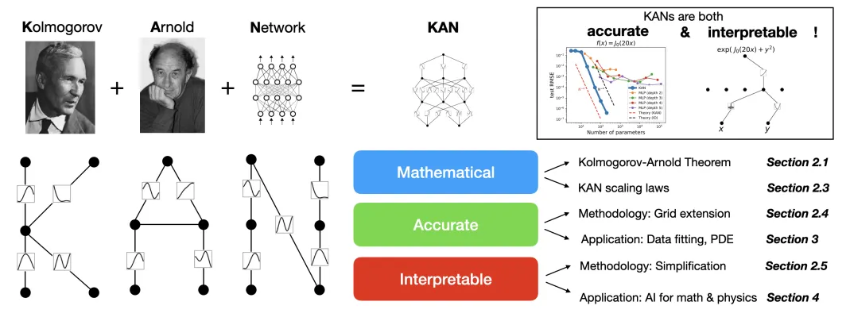
 2025
2025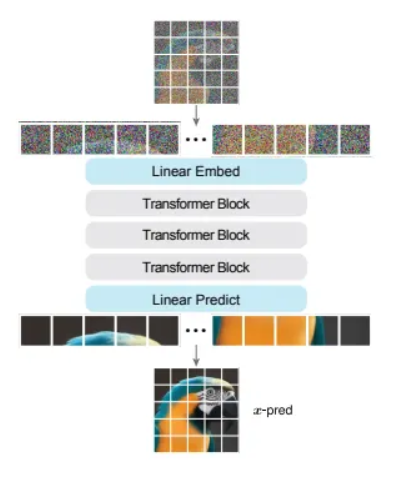 2025
2025